
Better software, better research
IMAS, Hobart, Tasmania
2024-01-31
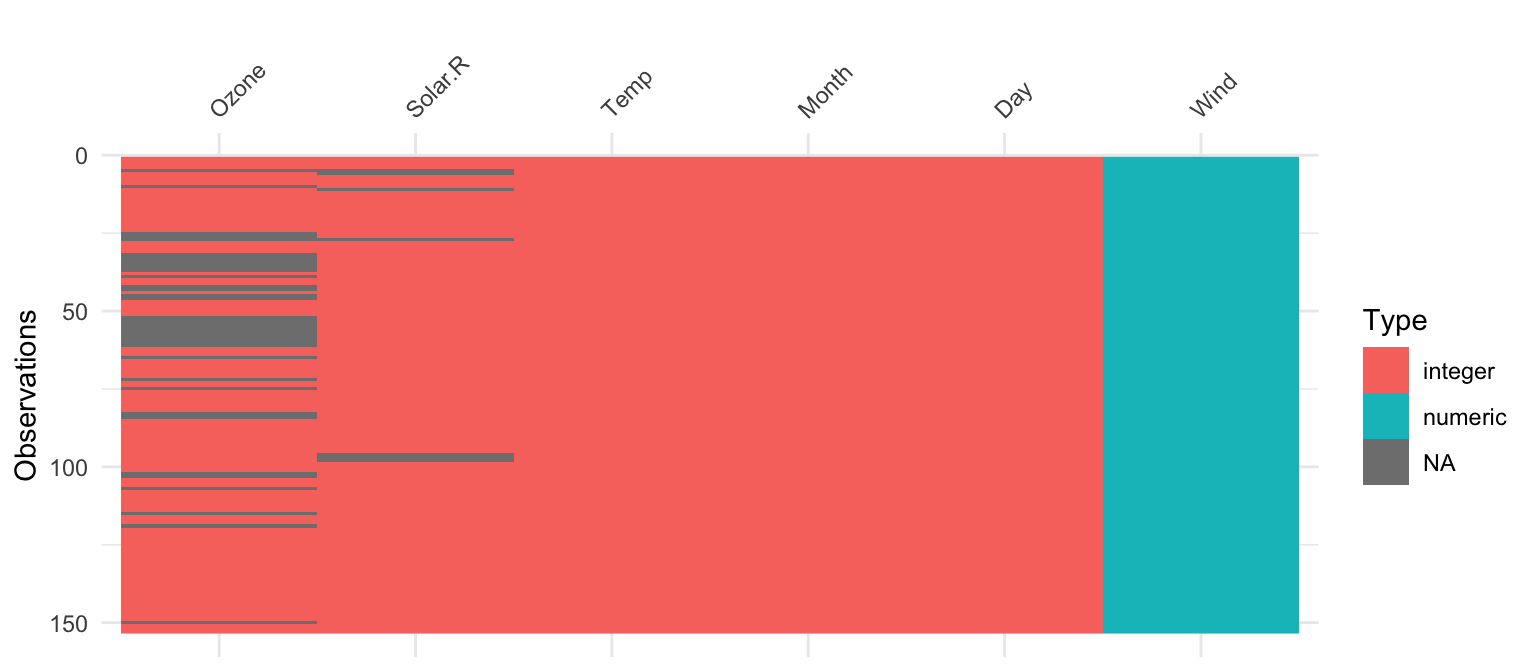
visdat::vis_dat(airquality)
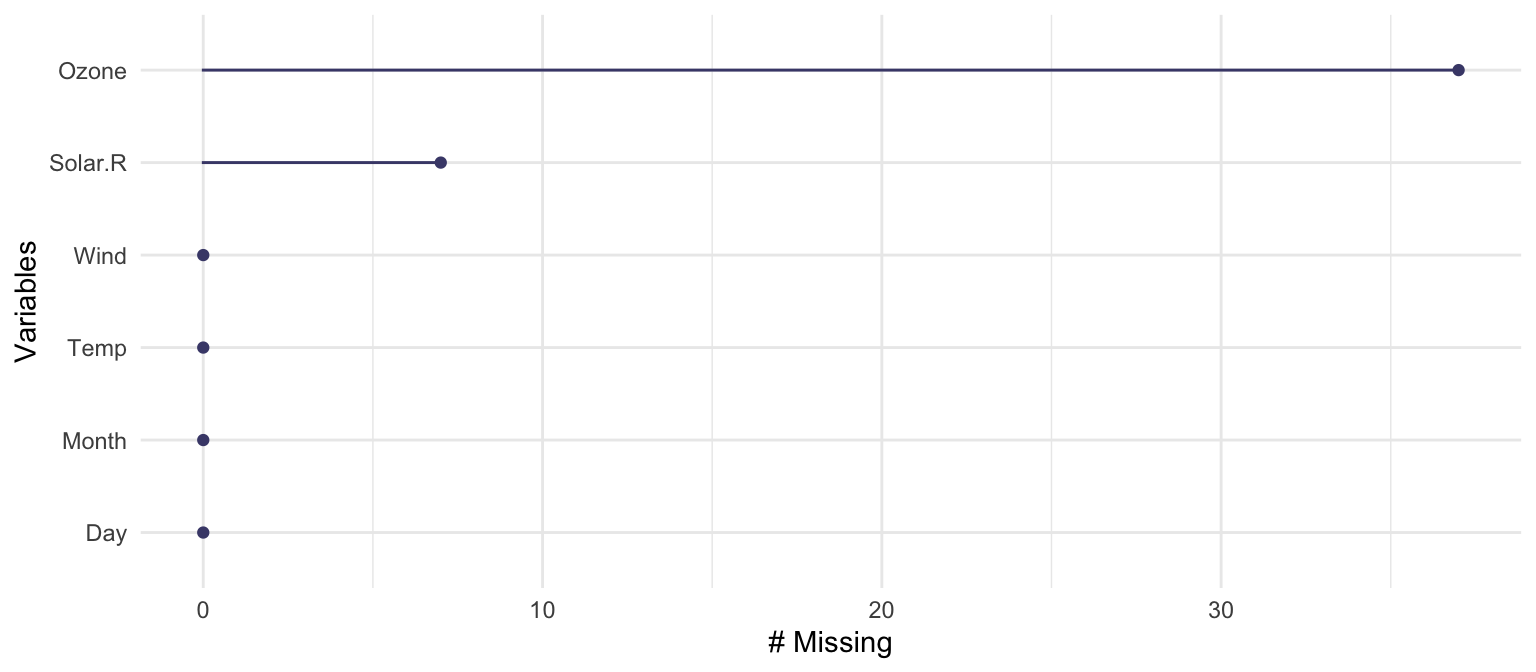
naniar::gg_miss_var(airquality)
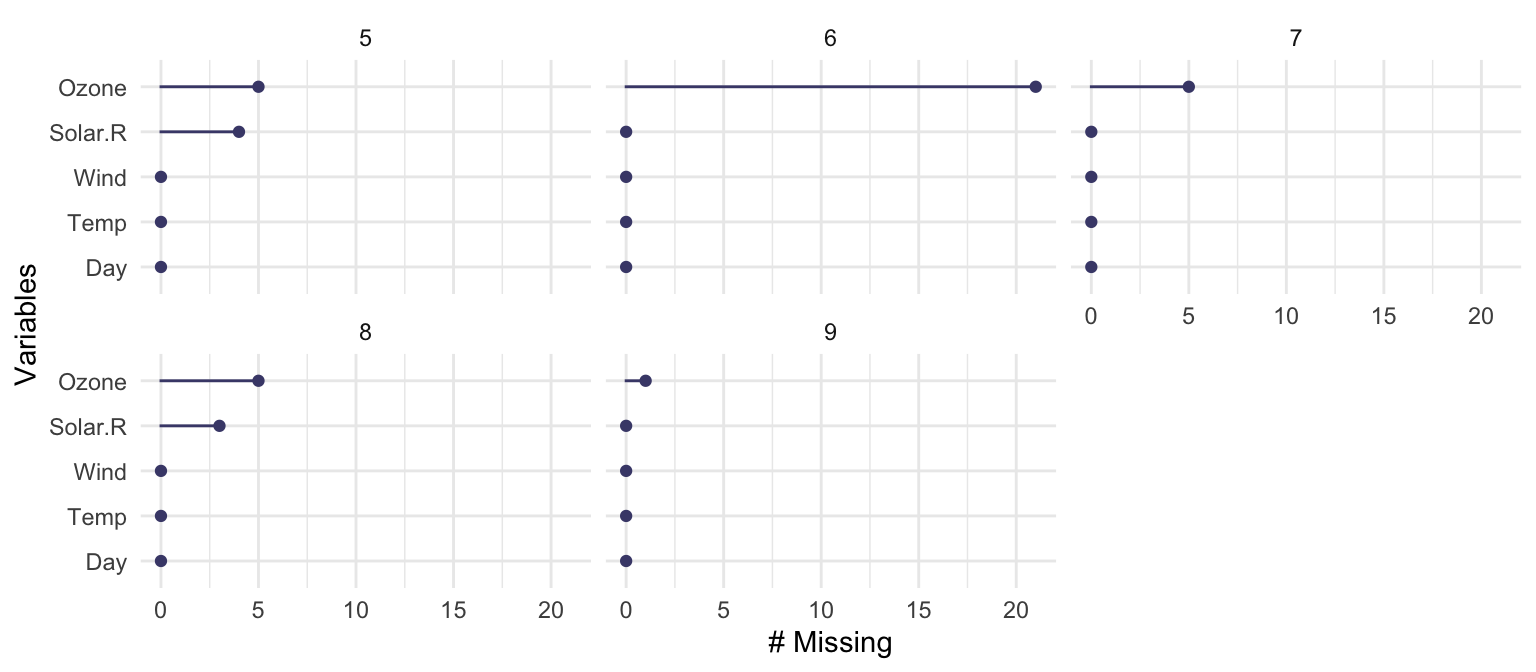
naniar::gg_miss_var(airquality, facet = Month)
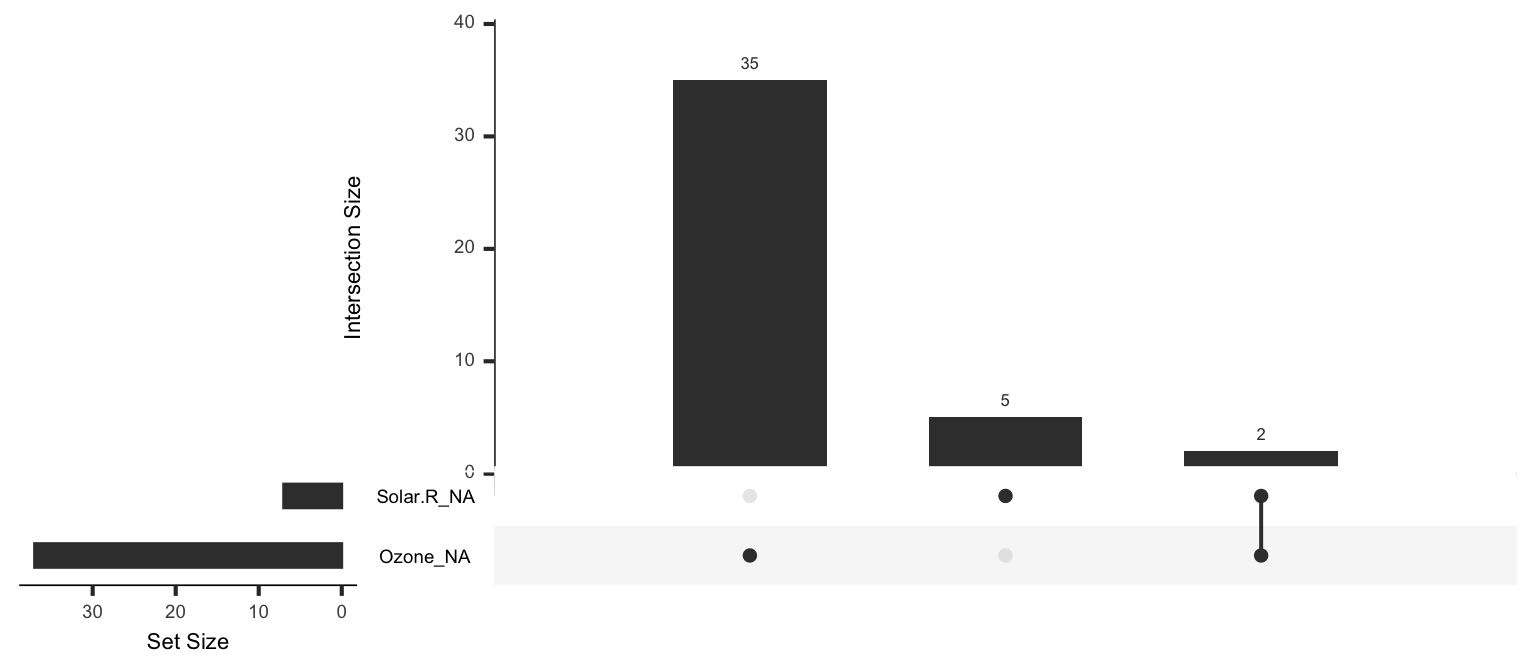
naniar::gg_miss_upset(airquality)
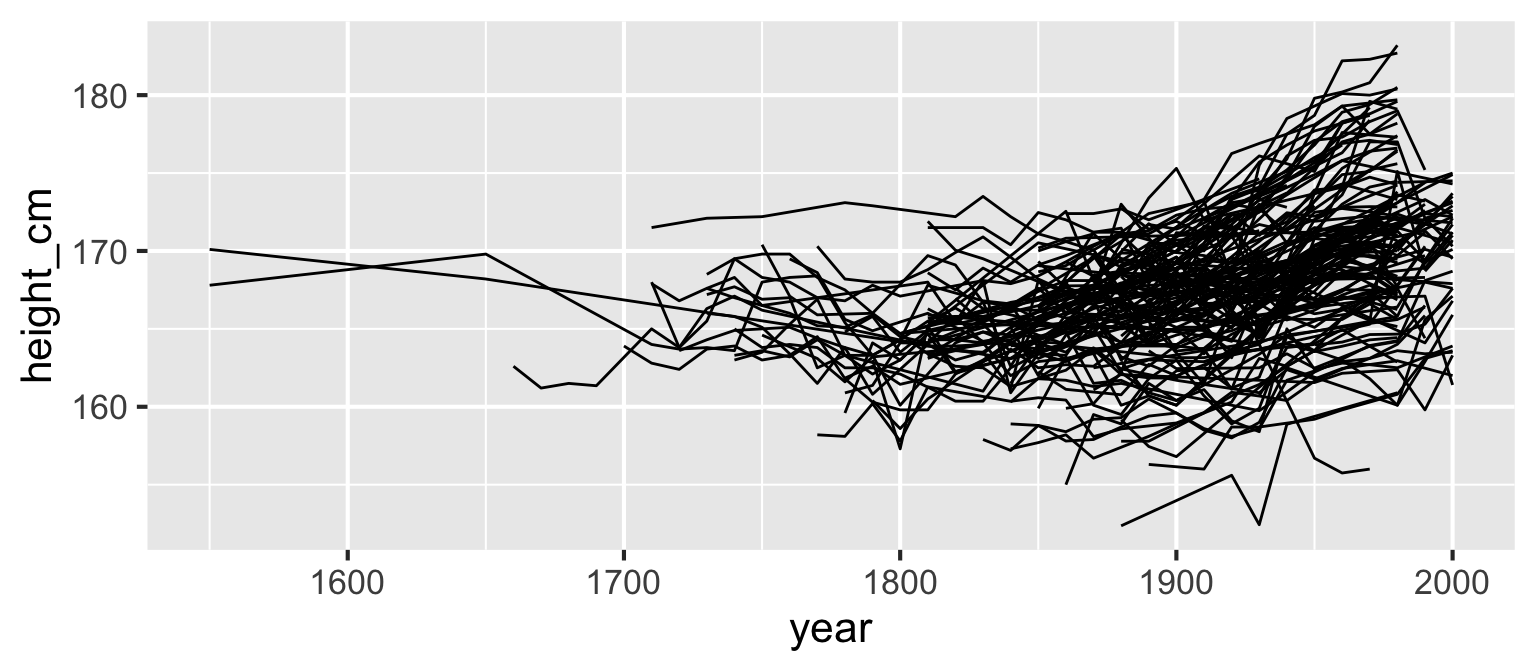
brolgar - take spaghetti
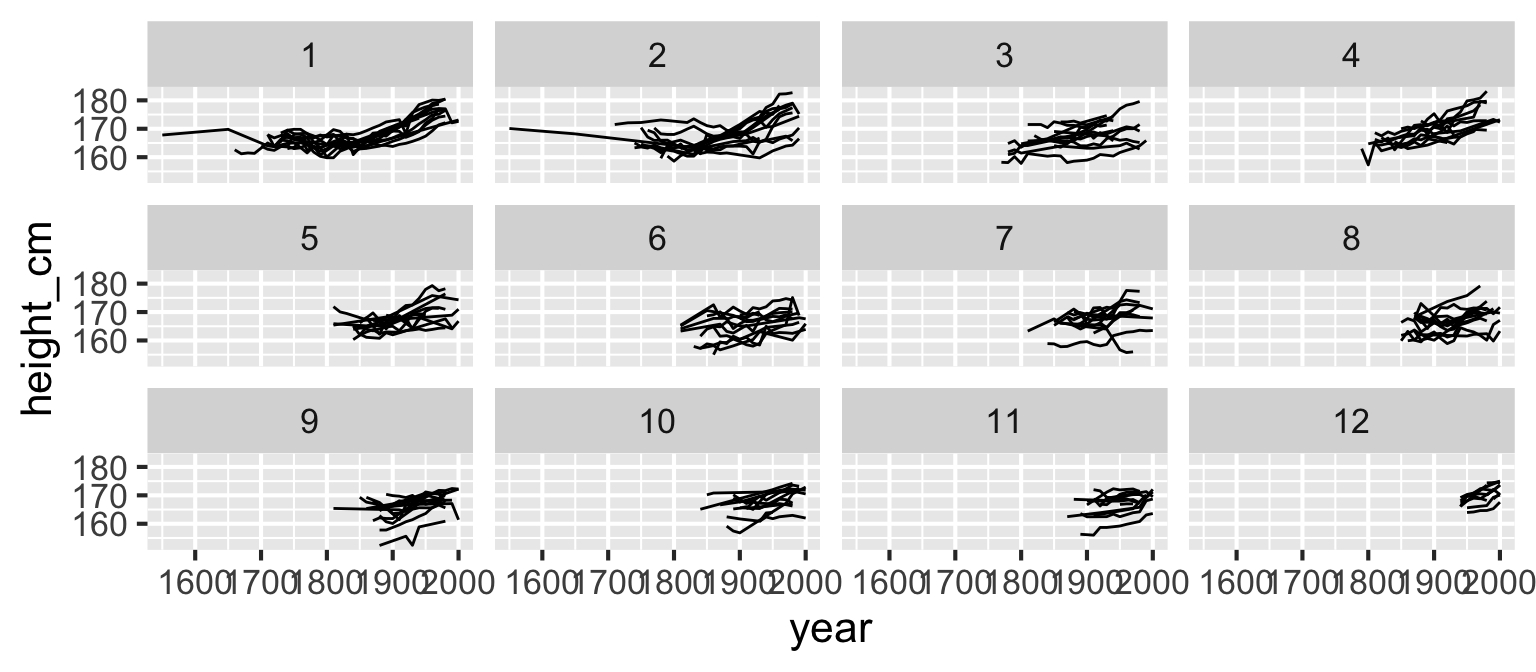
brolgar - spread spaghetti
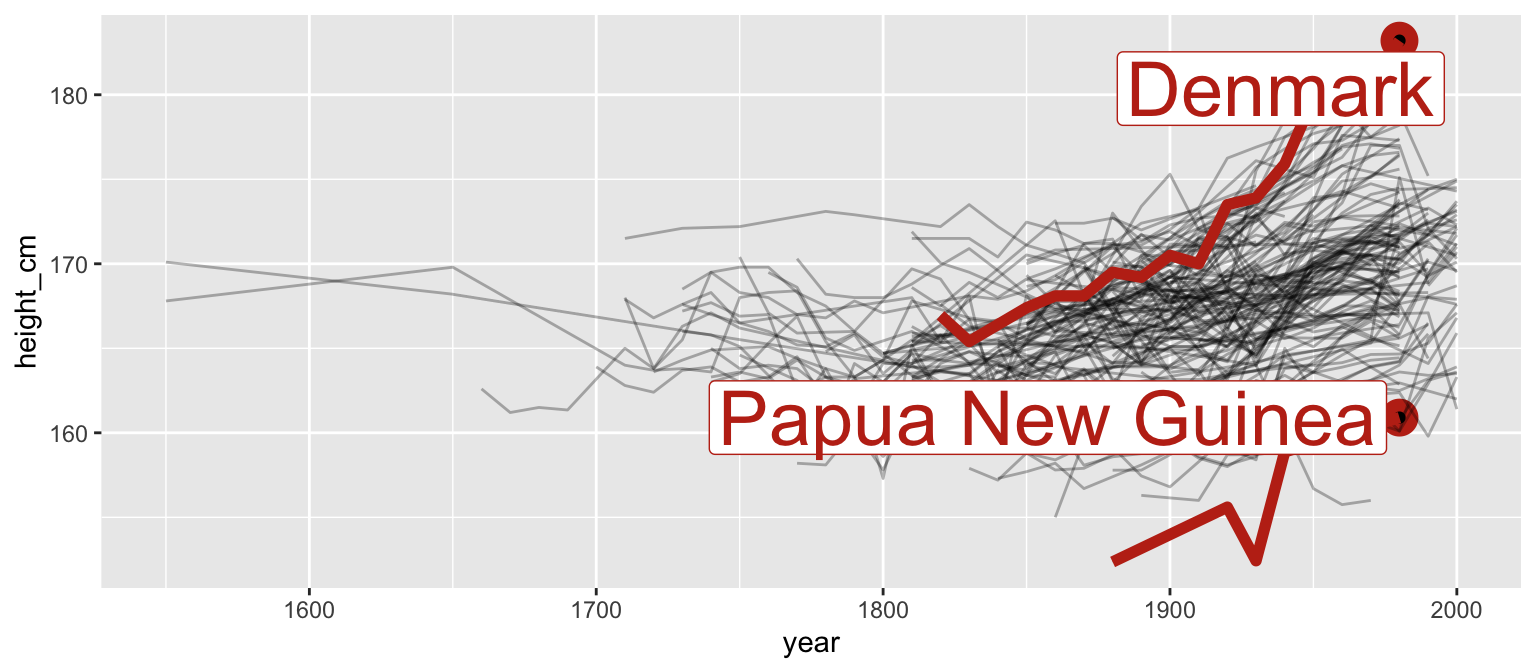
brolgar - identify spaghetti
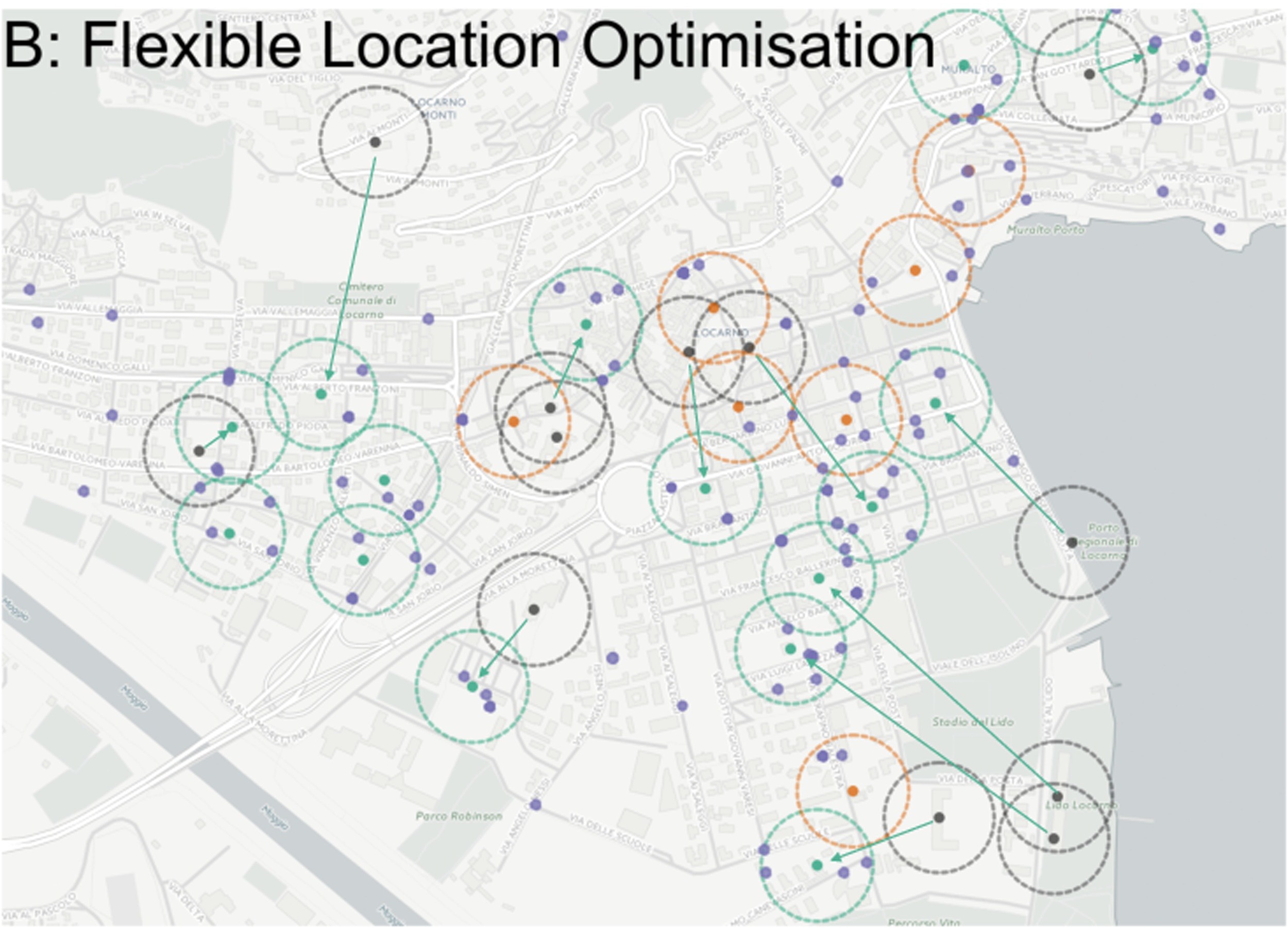
maxcovr - cover facilities
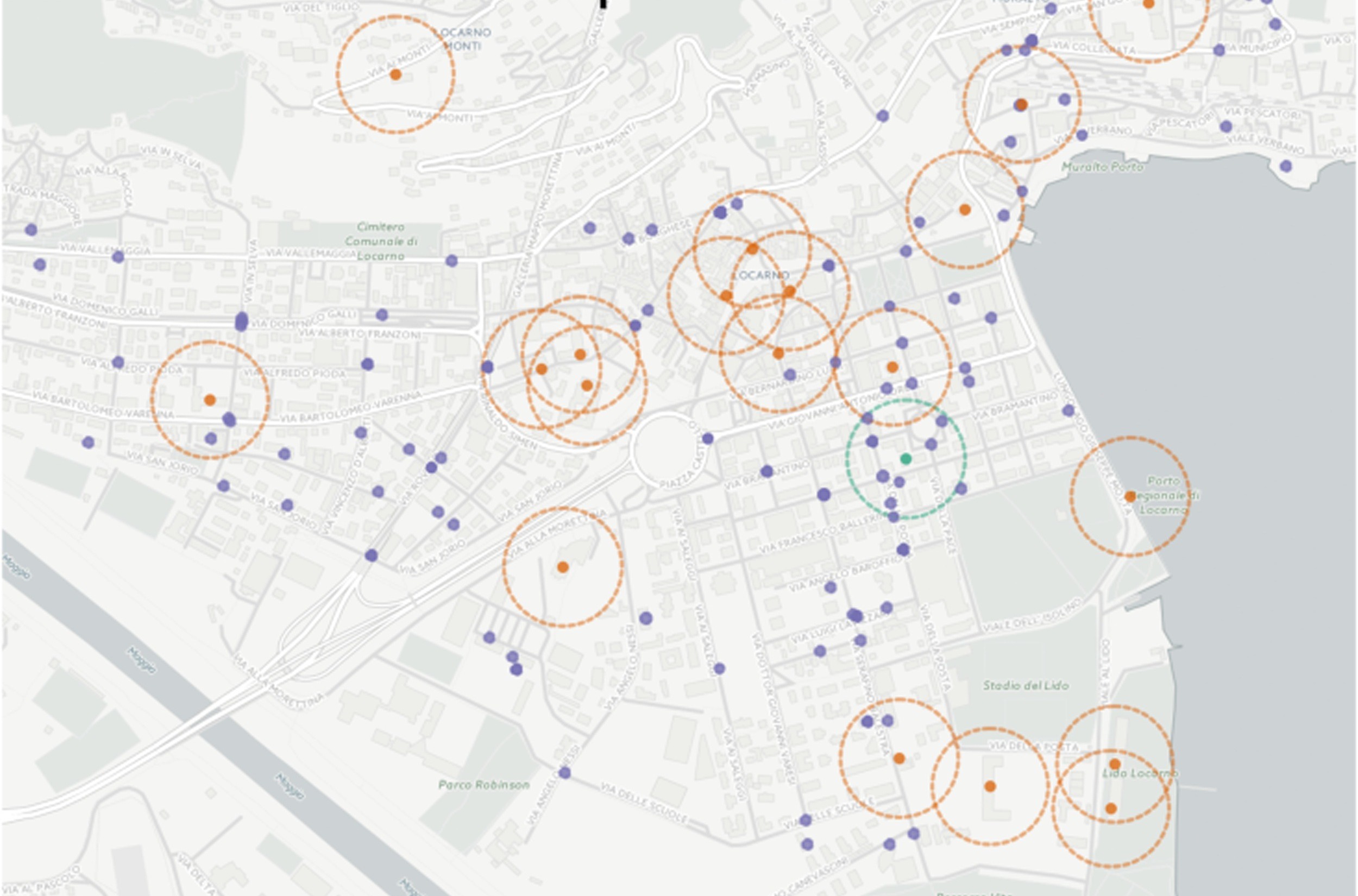
maxcovr - cover facilities
extendable
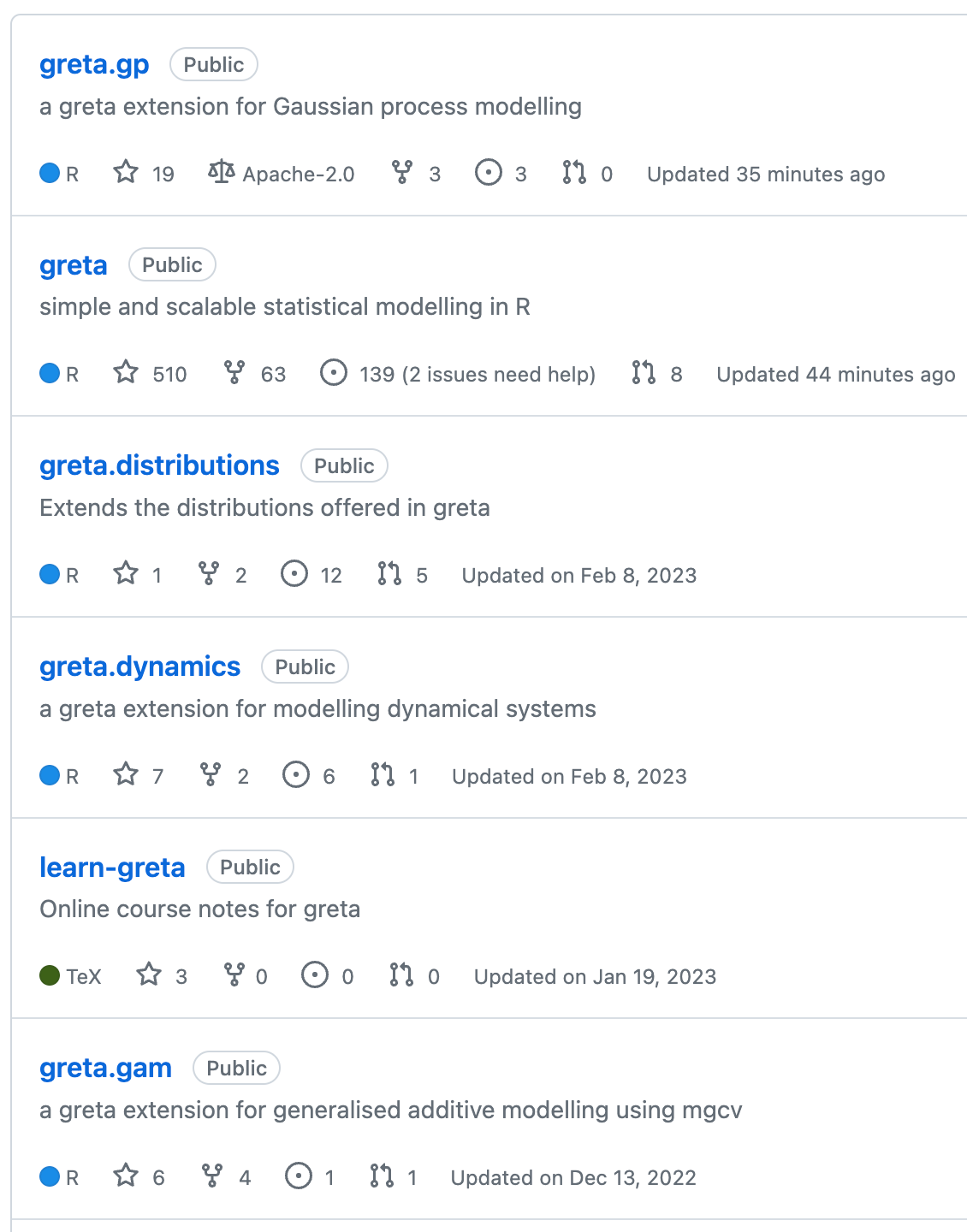
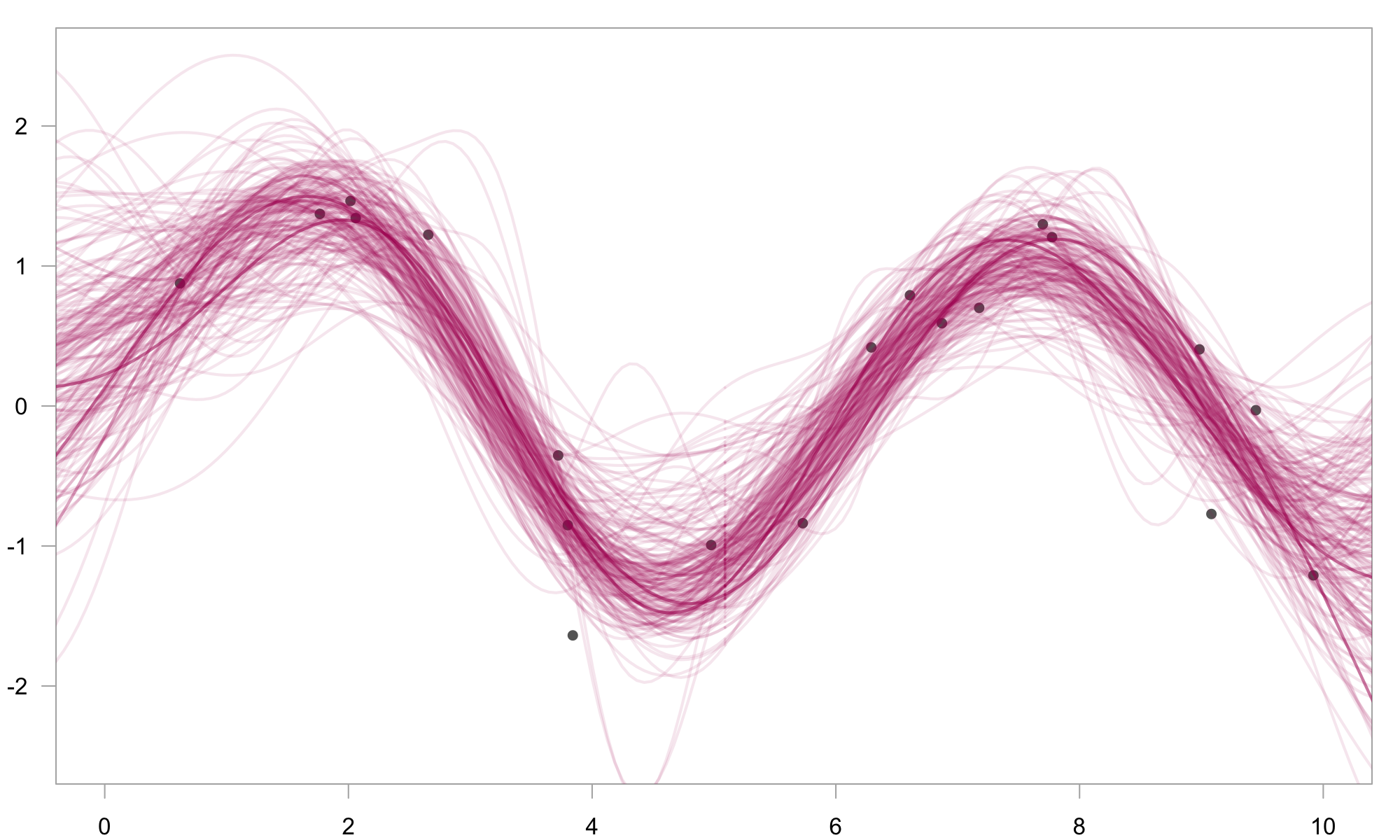
greta.gp
greta.gpextendsgretato let you define Gaussian processes as part of your model. It provides a syntax to create and combine GP kernels, and use them to define either full rank or sparse Gaussian processes.
why ‘greta’ ?
Grete Hermann (1901 - 1984)
wrote the first algorithms for computer algebra
… without a computer
(To avoid people saying ‘greet’, the package is spelled greta instead)
